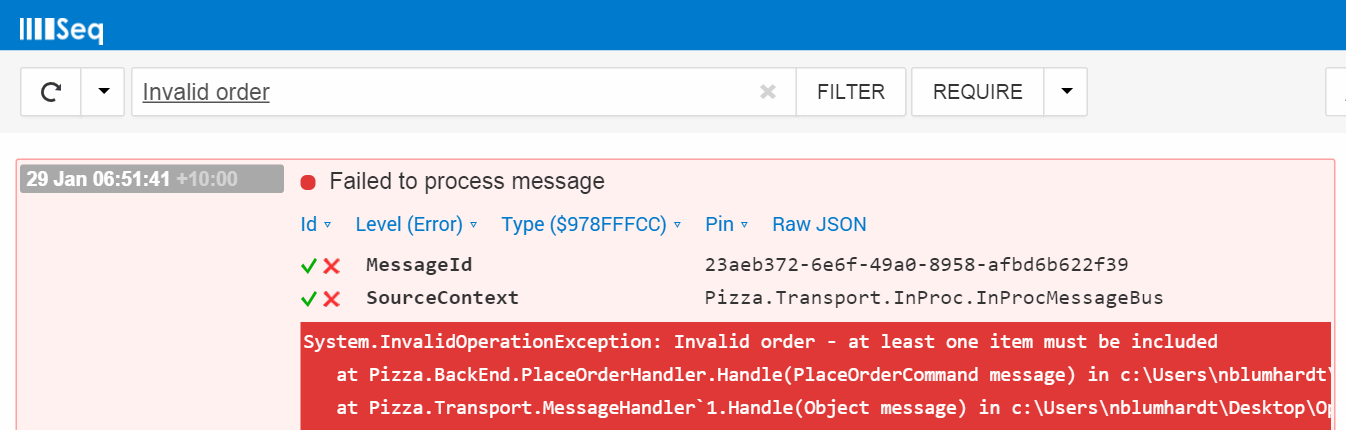
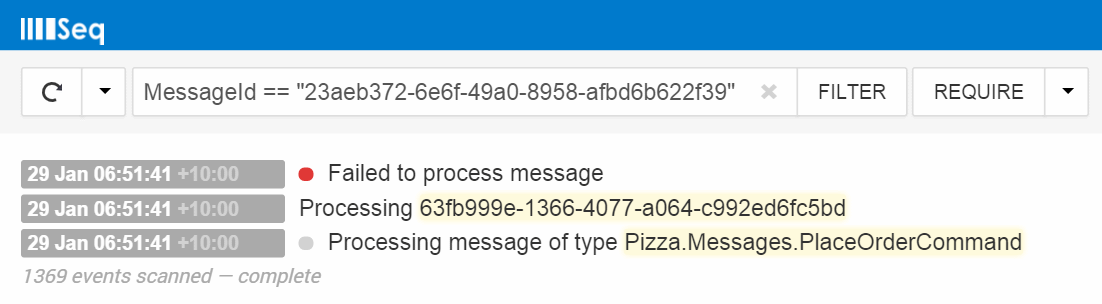
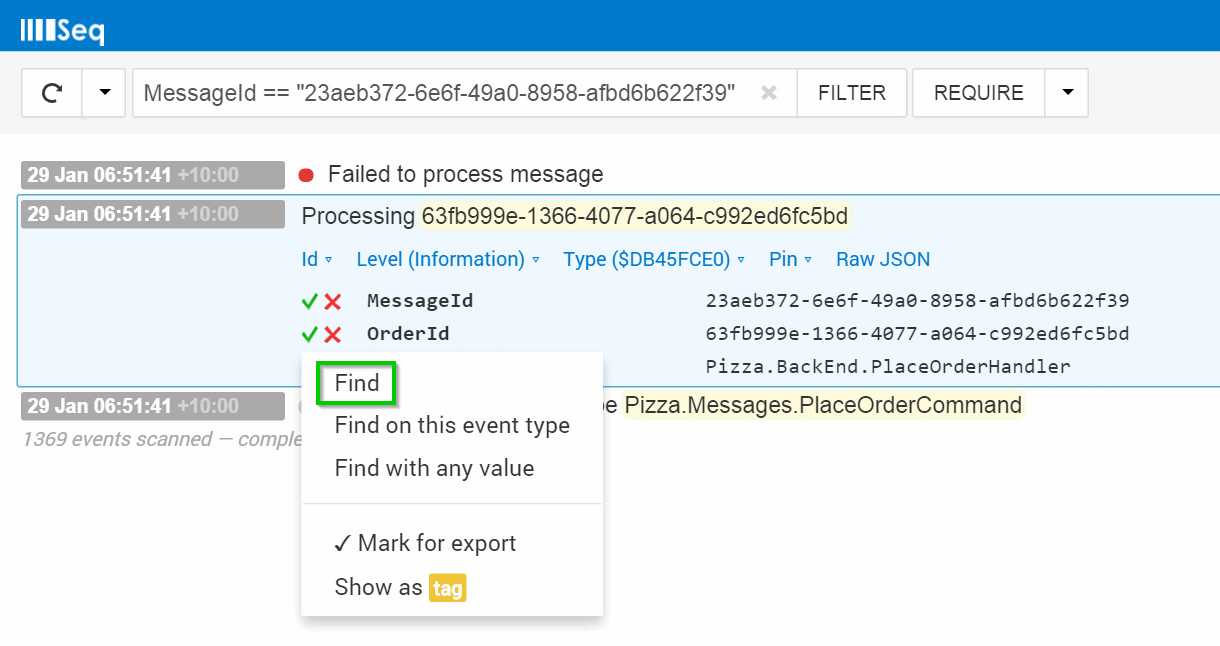
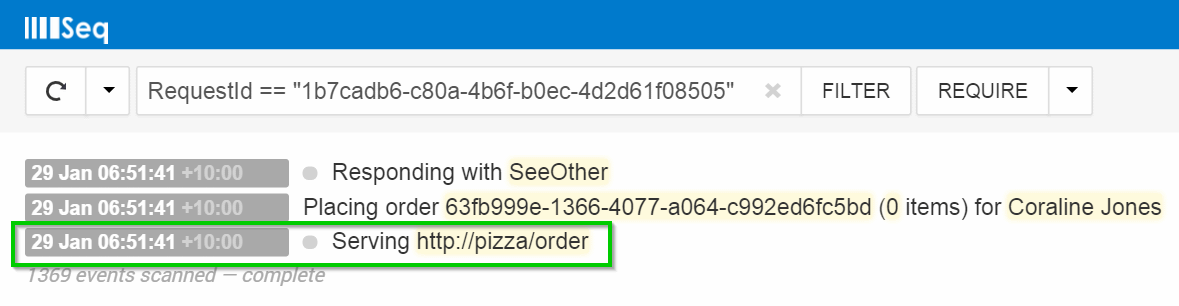
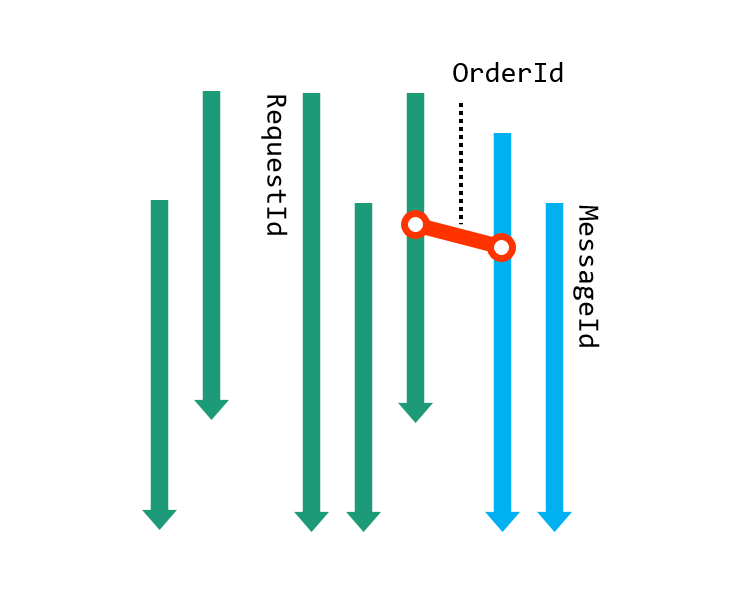
Perhaps the most useful, but seldom-noticed benefit of a structured log is having the first-class notion of an event type.
When analyzing a traditional text-based log, there’s no concrete relationship between the messages:
Pre-discount tax total calculated at $5.20
Customer paid using CreditCard
From a tooling perspective, each might as well be a unique block of arbitrary text. A lot of work’s required using tools like logstash to go further than that.
In a structured log from Serilog, the message template passed to the logging function is preserved along with the event. Since the first two come from the template:
While the third comes from:
We can use this information to unambiguously find or exclude either kind of event. It’s so simple and straightforward it is mind-boggling not to see this technique used everywhere!
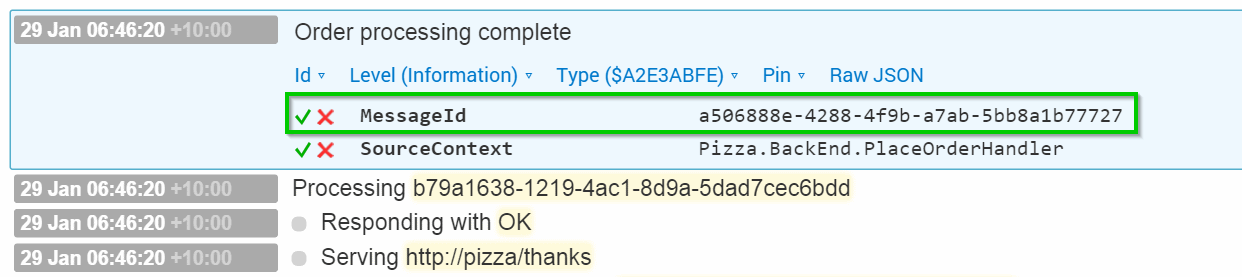
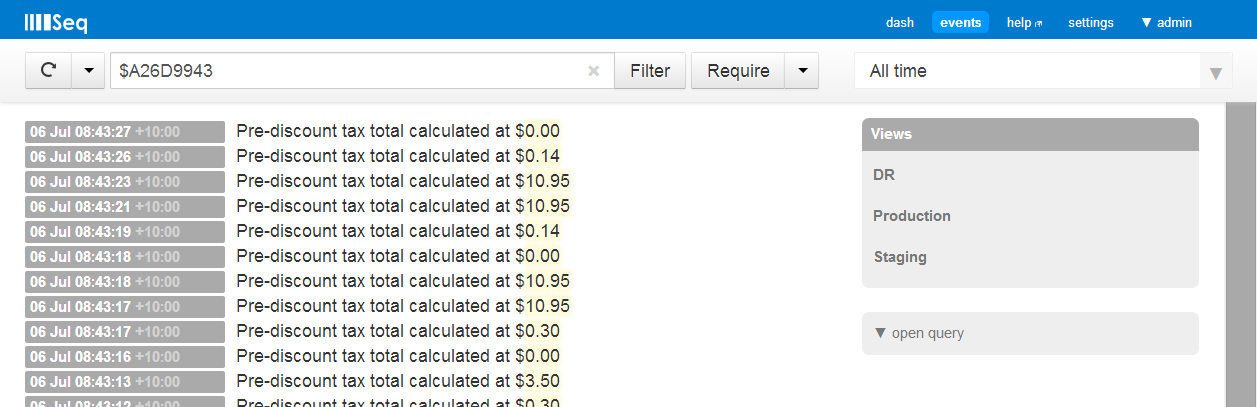
Working with message templates is verbose though, so Seq produces a 32-bit (Murmur) hash of the message template that can be referred to using hex literals, for example Pre-discount tax total calculated at {TaxAmount} → $A26D9943, while Customer paid using {PaymentMethod} → $4A310040.
Seq calls this the hash the “event type”. Here’s Seq selecting all events of the first type on my test machine:
This was for me, actually, one of the core reasons to justify spending a bunch of time on Serilog and Seq – application logs no longer seemed like a hack or a crutch: working with “real” events that have an actual type elevates them to something that can be usefully manipulated and programmed against.
So, what else can you do with a log imbued with first-class event types?
Event types and “interestingness”
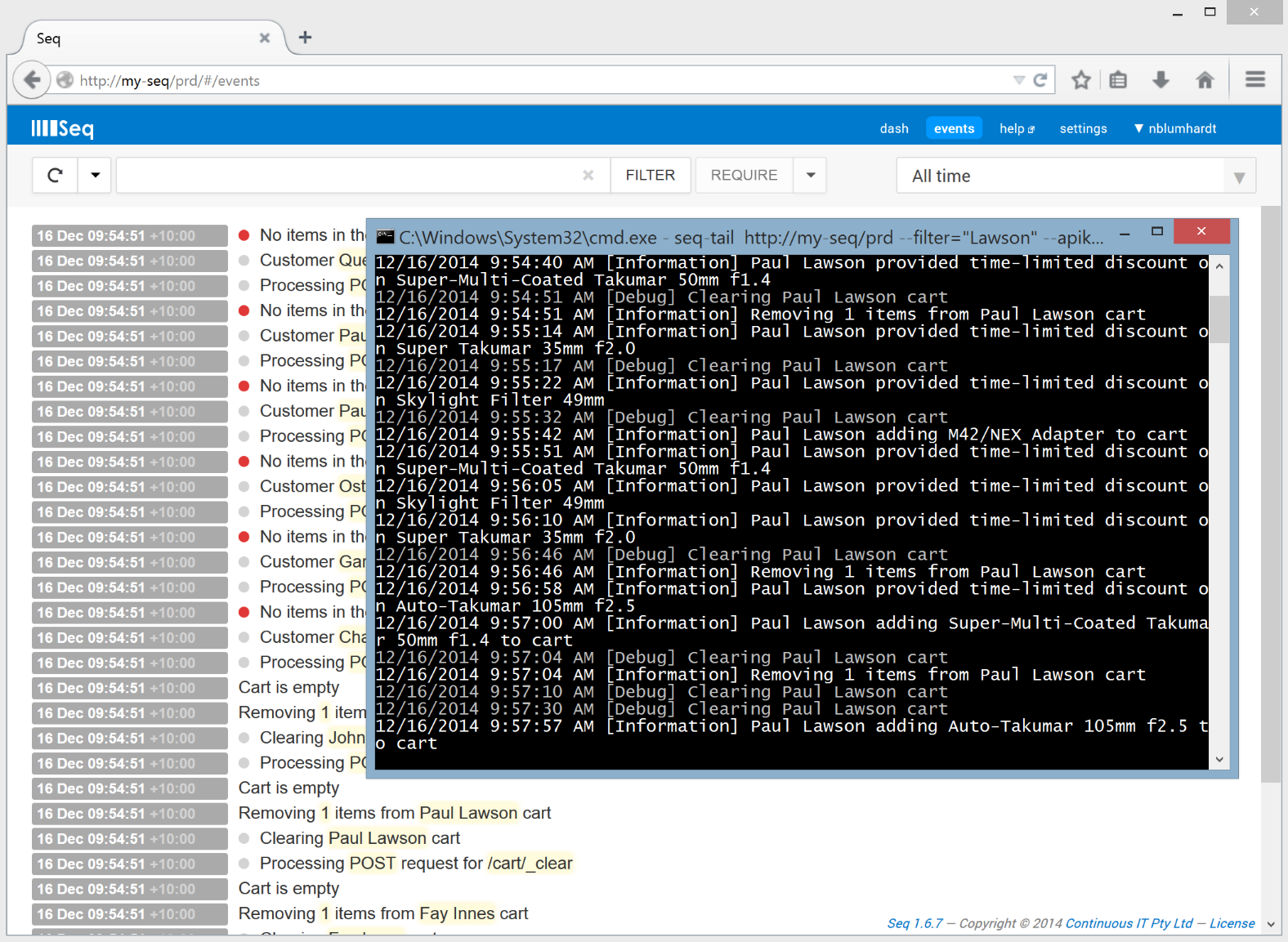
When I log into any of the Seq servers I maintain, they look much like this:
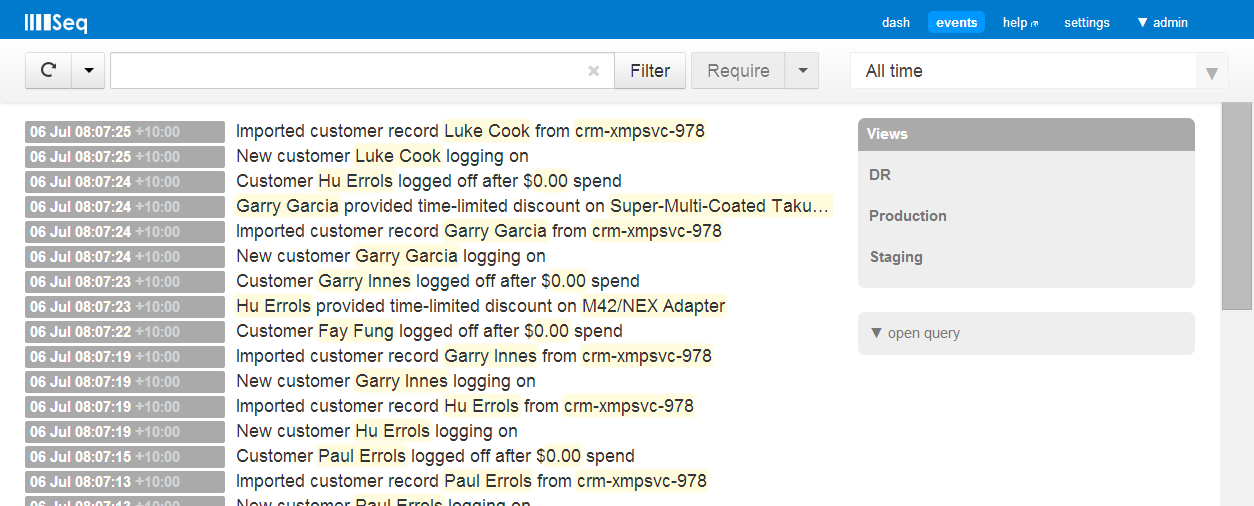
All seems pretty good – nothing out of the ordinary. Well, at least in the last minute or two…?! It’s really hard looking at a small window on a large event stream to make any proactive decisions, because by definition, the interesting events are a minority.
A compromise I use often is to create a view just for “Warnings and Errors” – unfortunately, on a large stream, this view’s not so useful either: the same kinds of things show up again and again. Diligently excluding uninteresting events by type can help here, but that’s a very manual process and isn’t much fun in practice.
Seq 1.4 introduces some simple local storage for hosted apps, so as a test case for that I’ve spiked a different approach to finding “interesting” events. Using some app-local storage, why not keep track of which event types we’ve seen before, and emit an event whenever something “new” happens?
For example, in the case:
{
Log.Information("The value is {Counter}", i);
}
We’d detect the event “The value is 0″ and then ignore further events with this event type (for values 1, 2, …). By keeping tabs on new events I might spot something unusual, or, I might just decide to incorporate the new event type into a counter or chart.
There’s a broader notion of “interestingness” than this of course, but for a simple example it’s still quite powerful.
First of Type
Here’s a new view on the same server shown earlier:
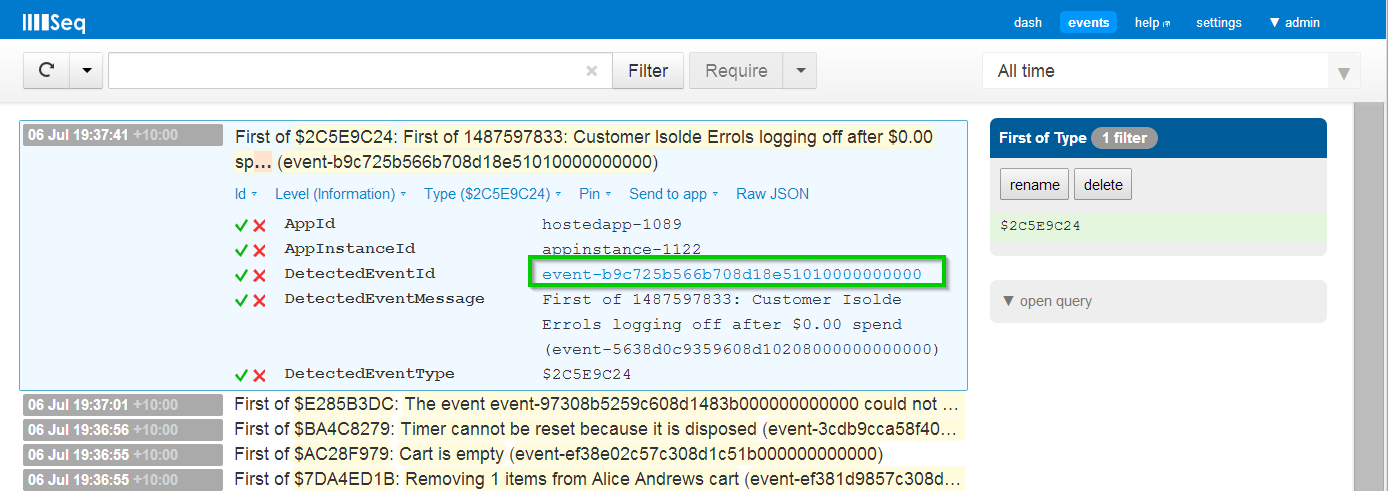
Rather than list the events themselves, we see the first occurrence of each event type and a hyperlink to view the event itself (shown in the expanded property view).
This view is generated by a new Seq app “First of Type”:
You can see the complete implementation with a few small improvements on GitHub, and install it into the Seq 1.4.4-pre build or later using the ID Seq.App.FirstOfType.
Once you’ve installed the app into your Seq server, “start a new instance of the app” that automatically accepts events, and click through to see the stream generated:
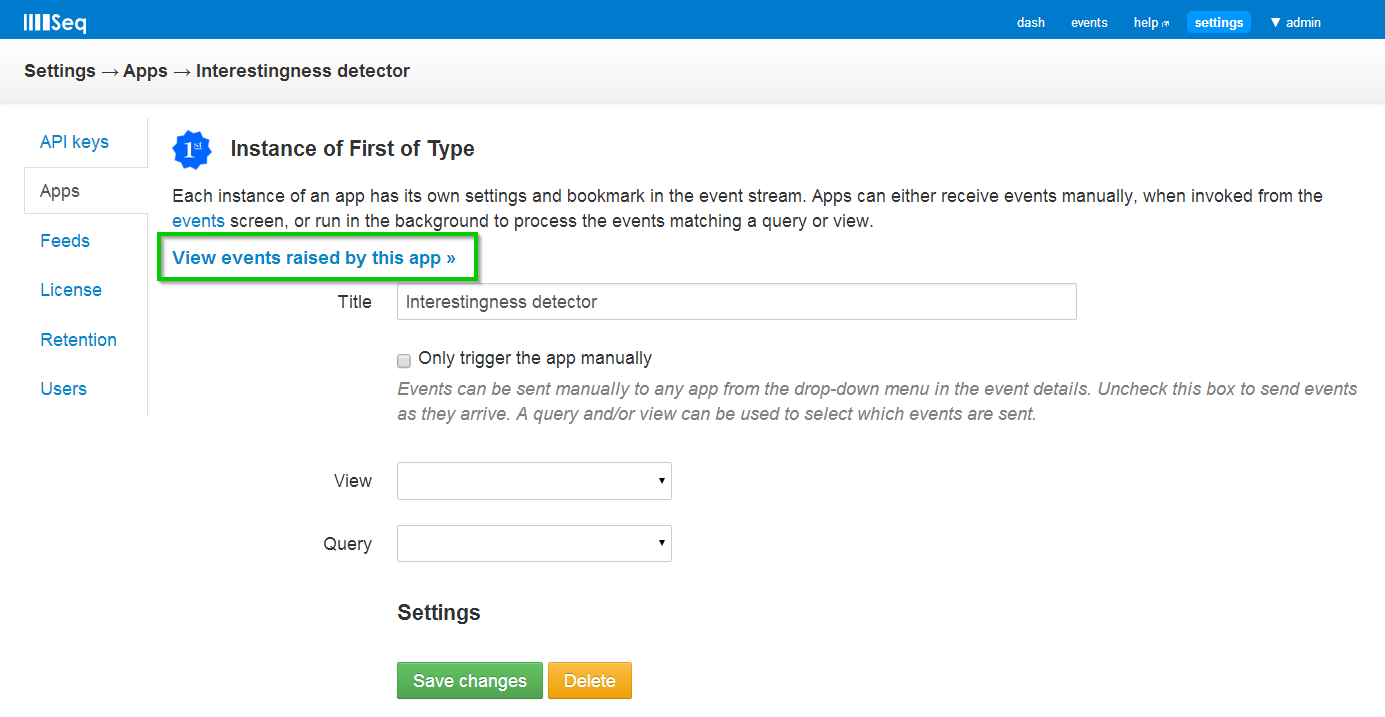
(You may need to wait for 30 seconds before the new app starts getting events: Seq uses a short buffer to sort events on arrival so that they are processed in timestamp-order).
So how’s it done?
The reactor implementation:
{
var stateFile = Path.Combine(StoragePath, StateFilename);
if (_filter == null)
{
if (File.Exists(stateFile))
_filter = new UInt32BloomFilter(File.ReadAllBytes(stateFile));
else
_filter = new UInt32BloomFilter();
}
if (!_filter.MayContain(evt.EventType))
{
Log.Information("First of {DetectedEventType}: {DetectedEventMessage} ({DetectedEventId})",
"$" + evt.EventType.ToString("X8"),
evt.Data.RenderedMessage,
evt.Id);
_filter.Add(evt.EventType);
File.WriteAllBytes(stateFile, _filter.Bytes);
}
}
The new feature that enables this is the StoragePath property, which simply provides a unique filesystem folder for the running app instance:
To keep runtime performance of the app and the size of the state file constant, we use a Bloom filter to track which event types we’ve seen:
The spike of the app as currently written uses a slightly smaller filter, and fewer hashes than desirable – if anyone’s interested in “doing the math” and setting up a better filter, PRs are accepted for this!
The language of the Bloom filter’s API – “may contain”, stresses that an approximation is being used:
This does mean that new types can be missed. Tuning the filter can bring this down to a negligible percentage.
The app emits an event using Log:
"$" + evt.EventType.ToString("X8"),
evt.Data.RenderedMessage,
evt.Id);
We don’t have to do anything special to get evt.Id hyperlinked in the Seq UI – the UI’s smart enough to detect this.
The rest of the app simply maintains the state file as event types are seen.
What’s Next?
I’ve often written log messages thinking “well, if I ever see this message I’ll know there’s a bug” – using this app there’s actually the possibility that I might notice a needle in the haystack!
It’s not a big leap from here to imagine a similar app that could track property values on an event type, either testing for uniqueness or observing variance from an historical range. Having local storage within Seq apps opens up a lot of possibilities I hadn’t given much thought to in the past. Happy hacking! :)