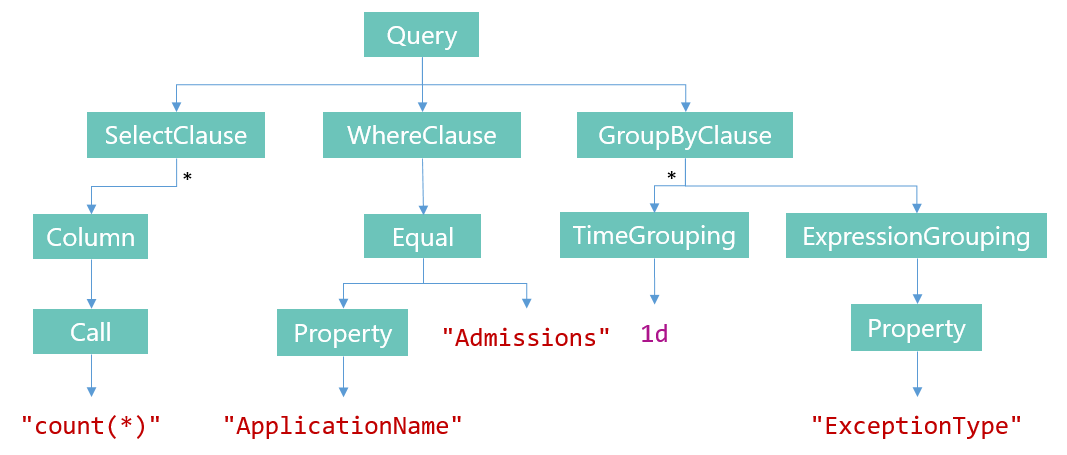
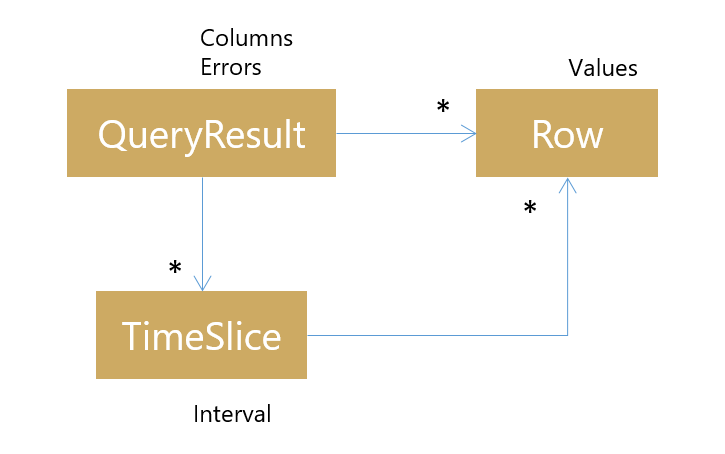
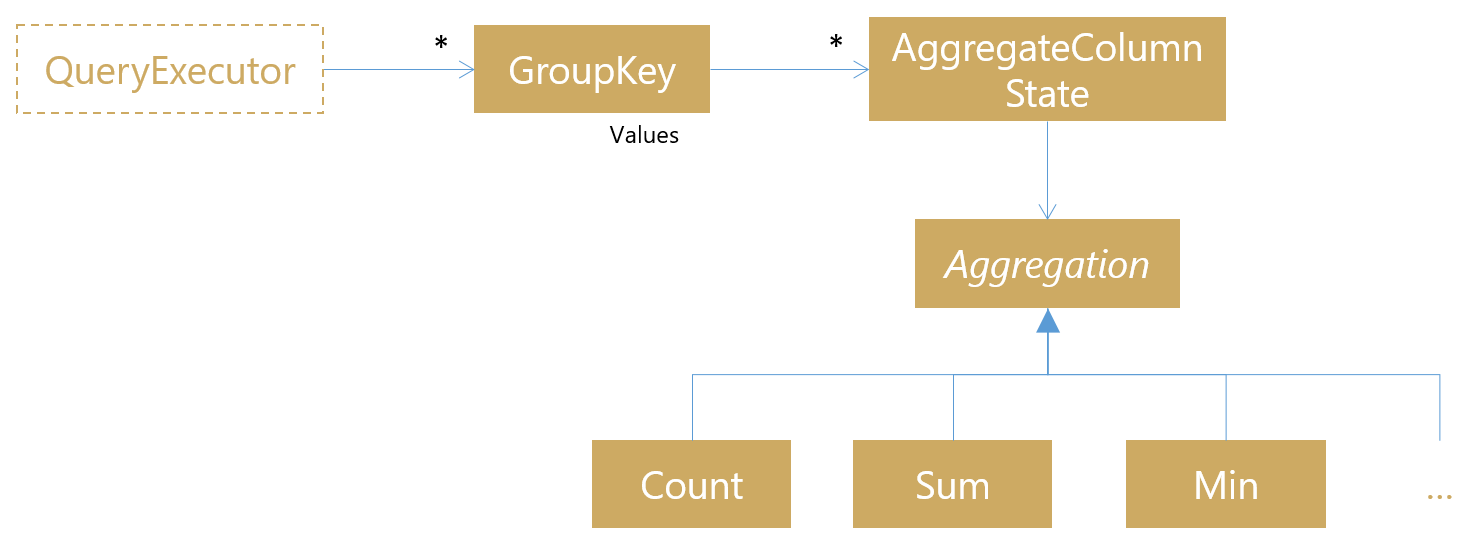
Let’s get it out of the way up front – I didn’t manage to fit this series into November. Hrmmmmm… sorry! In the end, I prioritised getting an early preview release out ahead of finishing the blog series documenting the process. The upside is – you can grab it now! The basics of aggregate queries, as they’ll appear in Seq 3, are in preview form on the Seq downloads page.
In what will be the final post in this series for now, I want to show you how the results of running an aggregate query are surfaced in Seq’s HTTP API, and also give a shout-out to some handy tools and techniques it uses along the way.
A syntactic digression…
Before we dive into how Seq’s API is structured, there’s one small tweak to the “SQL-like” query language that I should mention. To avoid endless confusion about what that “-like” really means, the new syntax added in Seq 3 will, as much as possible, be a dialect of SQL. Introducing fewer new things means everyone has less to hold in their head while using Seq, which fits Seq’s goal of getting out of the way while you navigate logs.
The most noticeable change here is that all queries (except trivial scalar ones such as select 41 + 1 as Answer) now have a from clause of the form from stream. The “stream” is Seq’s way of describing “whichever stream of events you’re currently looking at”. Someday other resources wll be exposed through the query interface, and the from clause will enable that.
Other changes you’ll spot are support for SQL operators such as and, or, not and even like. Single-quoted strings are supported, as are SQL comparisons = and <> (though a bug in the published build prevents the use of the latter).
By aligning better with SQL I hope Seq’s querying facilities can remain easy to learn while evolving to support more sophisticated uses.
Resources and Links
Back to the API. Seq is developed API-first, a strategy I picked up from Paul Stovell while working on Octopus Deploy, and something that’s made a huge impact on the way I’ve approached web application development ever since.
Seq also employs some of the ideas associated with hypermedia APIs, notably links and URI templates. (In my experiences so far these are the techniques, along with semantic use of HTTP verbs, that have delivered the most value in application development. Some of the more sophisticated hypermedia concepts like custom media types for standard interchange formats are very interesting but I’m not seeing much use day-to-day. Having said that, wurl is one tool I’ve seen that made me wish we all did use HAL or JSON-API.)
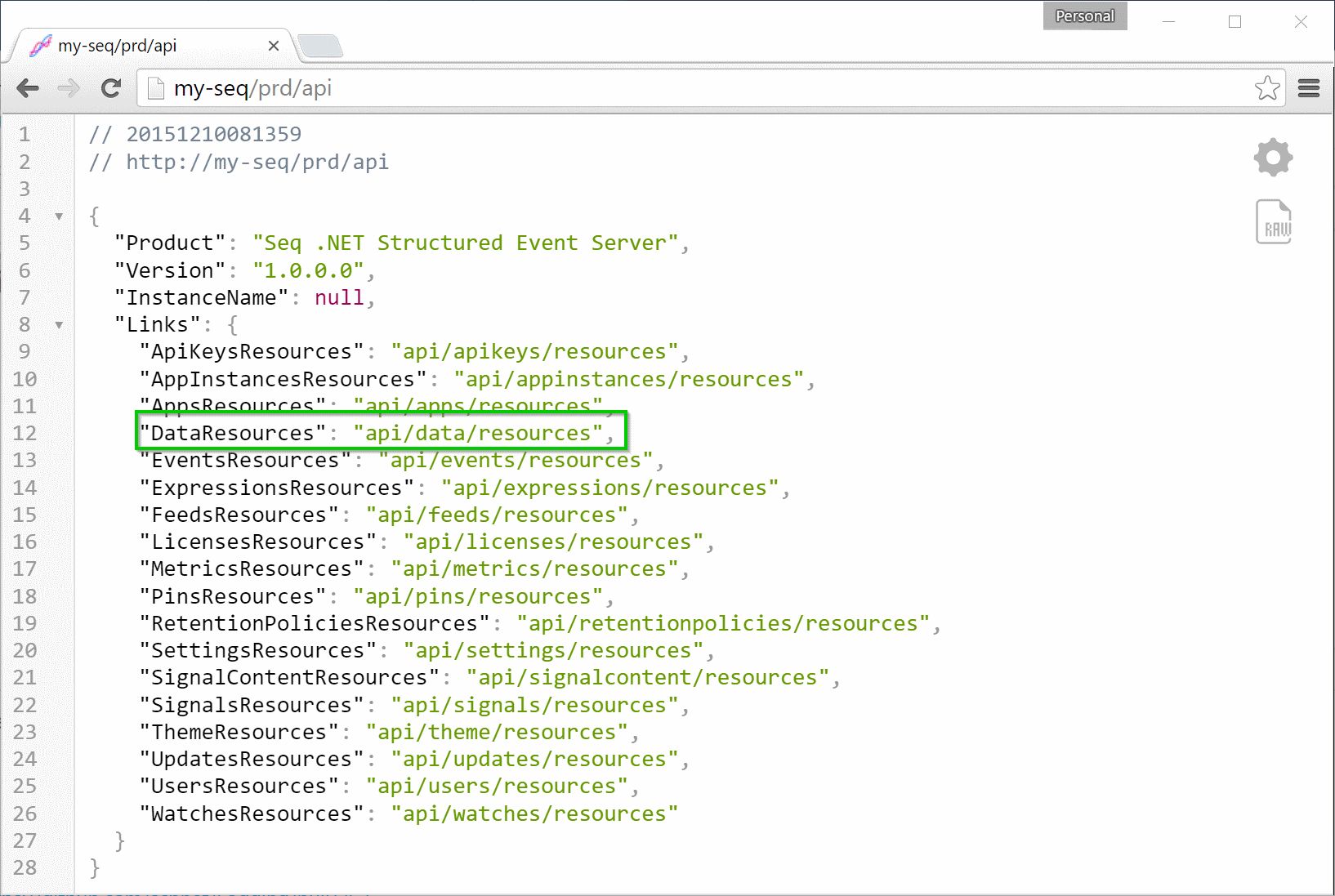
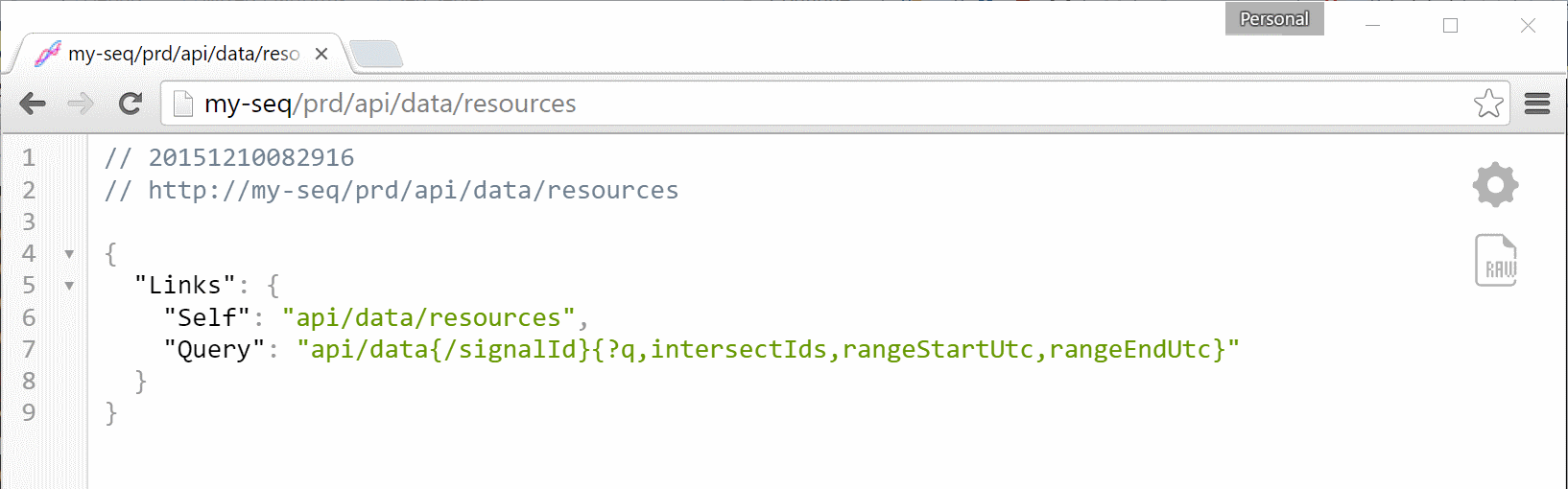
Linking means that the entire Seq API can be navigated from a single root document. At https://your-seq-server/api (here if you’re on localhost) there’s a JSON document with links into all the various resources that the server provides.
![API Root]()
The green box (shout out to Greenshot) shows the resource endpoint where queries are going to be exposed as data sets.
My test Seq instance is configured to listen under the /prd URL prefix, but unless you’ve set this up explicitly you won’t see this part of the path on your own instance.
![Data Resources]()
I’ll admit that there isn’t much of hypermedia angle in this particular use case – rowsets aren’t obviously entities the way signals, users and event events are in Seq’s world-view – but using the same machinery for this as the remainder of the API keeps everything working harmoniously.
The awesome thing from a consumer standpoint though, is the self-documenting nature of the whole thing. Note the "Query" link in the image above. This is a URI template describing how calls to the query endpoint should be formatted.
GET http://your-seq-server/api/data?q=select%20count(*)%20from%20stream&rangeStartUtc=2015-12-08T22:20:22.000Z HTTP/1.1
The signalId segment of the URI is optional, so it doesn’t appear in this request.
In the JavaScript client the call looks like:
api.data.query({ q: 'select count(*) from stream', rangeStartUtc: start }).then(rowset => {
// rowset is the query result
});
Here, if the client did specify a signalId, the URI template ensures it would be formatted into a URL segment rather than being specified as a query string parameter like the other parameters are, but the client code doesn’t have to be aware of the difference. This makes it nice and easy to refactor and improve the URL structure of the API (even during development) without endlessly poking around in JavaScript string concatenation code.
On the client side, URI templates are handled with the Franz Antesberger’s JavaScript implementation. For the most part this means a hash of parameters like the argument passed to query above can be substituted directly into the URI template, and validated for correct naming and so-on along the way.
Serving it up with Nancy
On the server side, NancyFX reigns. Like Octopus Deploy, Seq took a bet on Nancy in its pre-1.0 days and hasn’t looked back. The team behind Nancy is talented, passionate, but above all, highly considerate of its users to the extent that since adopting Nancy in the zero-point-somethings there’s barely been any breakage or churn between versions, let alone bugs. I can’t recommend Nancy highly enough, and consider it the gold standard for building web apps in .NET these days. It looks like I’m not alone in this opinion.
I find Nancy wonderful for building APIs because while it exposes a slightly quirky API of its own (a noble thing!), it isn’t at all opinonated about how you should structure yours. This also means that when dealing with Nancy there are sensible defaults everywhere, but very little deeply built-in policy – so minimal time is spent grappling with the framework itself.
Here’s the route that handles queries:
public class DataModule : SignalContentModule
{
readonly Lazy<IEventStore> _events;
public DataModule(Lazy<IEventStore> events)
: base("data")
{
_events = events;
Post[""] = p => Query(SignalsModule.MapToNewDocument(ReadBody<SignalEntity>()));
Get["/{signalId}"] = p => Query(LoadAndCheck(p.signalId));
}
This is a Nancy module that shares some functionality with the events module (though implementation inheritance does feel like a bit of an ugly hack, here as elsewhere). The two different instantiations of the Query URI template we viewed before need two routes in Nancy; the POST version accepts an unsaved signal in the body of the request, which is necessary because signals may be edited in the UI and queries run against them without saving the changes.
There’s one snippet responsible for declaring how the module works:
protected override ResourceGroup DescribeResourceGroup()
{
var resource = base.DescribeResourceGroup();
resource.Links.Add("Query", Qualify("{/signalId}{?q,intersectIds,rangeStartUtc,rangeEndUtc}"));
return resource;
}
(I’ve often thought it would be nice to unify the description with the routing – there’s some duplication between this code and the route configuration above.)
I’ll include for you here the whole implementation of Query() in all its SRP-violating glory (I think the un-refactored version is nicer to read sequentially in a blog post, but as this goes from feature spike to a fully-fledged implementation I see some Ctrl+R Ctrl+M in the very near future):
Response Query(Signal signal = null)
{
var query = (string)Request.Query.q;
if (string.IsNullOrWhiteSpace(query))
return BadRequest("A query parameter 'q' must be supplied.");
DateTime? rangeStartUtc = TryReadDateTime(Request.Query.rangeStartUtc);
DateTime rangeEndUtc = TryReadDateTime(Request.Query.rangeEndUtc) ?? DateTime.UtcNow;
if (rangeStartUtc == null)
return BadRequest("A from-date parameter 'rangeStartUtc' must be supplied.");
if (rangeStartUtc.Value >= rangeEndUtc)
return BadRequest("The queried time span must be of nonzero duration.");
var filter = GetIntersectedSignalsFilter(signal);
var result = _events.Value.Query(
query,
rangeStartUtc.Value,
rangeEndUtc,
filter: filter);
if (result.HasErrors)
{
var response = Json(new QueryResultPart
{
Error = "The query could not be executed.",
Reasons = result.Errors
});
response.StatusCode = HttpStatusCode.BadRequest;
return response;
}
var data = new QueryResultPart
{
Columns = result.Columns,
Rows = result.Rowset,
Slices = result.Slices?.Select(s => new TimeSlicePart
{
Time = s.SliceStartUtc.ToIsoString(),
Rows = s.Rowset
}).ToArray(),
Statistics = new QueryExecutionStatisticsPart
{
ElapsedMilliseconds = result.Statistics.Elapsed.TotalMilliseconds,
MatchingEventCount = result.Statistics.MatchingEventCount,
ScannedEventCount = result.Statistics.ScannedEventCount,
UncachedSegmentsScanned = result.Statistics.UncachedSegmentsScanned
}
};
return Json(data);
}
I have come to wonder if anyone out there uses optional = null parameters as a semi-self-documenting “nullable” annotation for parameters like this:
Response Query(Signal signal = null)
{
I picked it up as a habit after Daniel Cazzulino (if my memory serves me correctly) suggested it as a way of marking optional dependencies in Autofac. Using a default value for nullable arguments expresses the intent that ? would, had nullability been first-class in the early days of C#.
The block of code all the way through to the initialization of filter slurps up parameters from the query string. Nancy has a binding system that might knock a line or two of code out here.
The real action is in:
var result = _events.Value.Query(
query,
rangeStartUtc.Value,
rangeEndUtc,
filter: filter);
IEventStore.Query() is a wrapper method where the parsing, planning and execution steps take place.
Finally, the result is mapped back onto some POCO types to send to the caller. No magic here – but then again, I think the theme of these few blog posts has been to cut through the whole implementation in an anti-magical way. The types like QueryResultPart will eventually make their way to the Seq API client.
And that, my friends, is a wrap! It’s been fun sharing the process of spiking this feature. I’d like to continue this series into the Seq UI, but there’s a lot to do in the next few months as Seq 3 comes together into a shippable product. I’m excited about how much aggregate queries will enable as part of that. In the meantime though I need to report on the progress that’s been happening in Serilog in preparation for cross-platform CoreCLR support and ASP.NET 5 integration – look out for an update on that here soon.
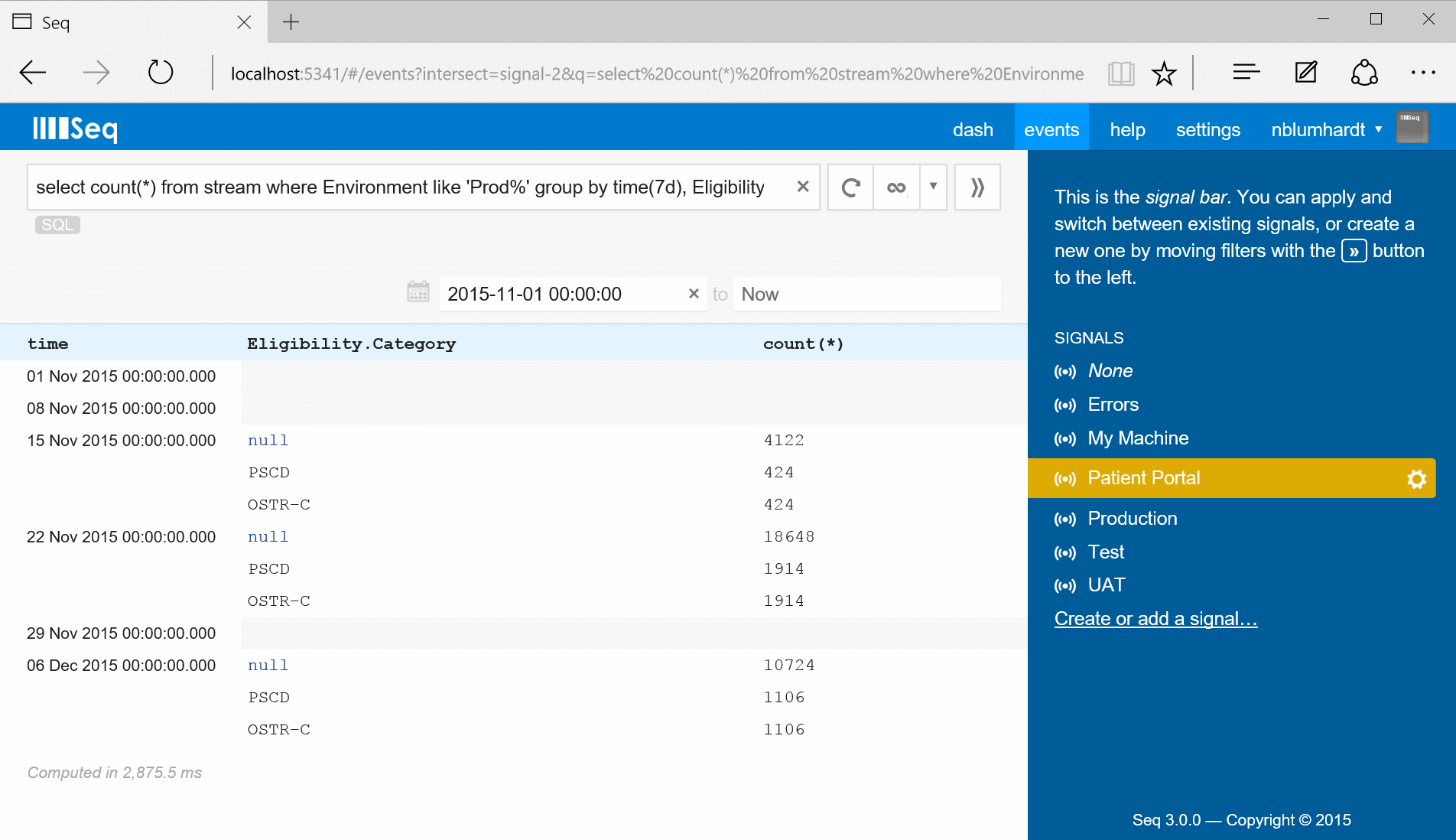
I’ll leave you with a snapshot of an aggregate query in action.
![Screenshot]()
Download the 3.x preview installer here and check out the documentation here.